We've all been there, countless hours sifting through line after line of a log file to find that needle in a haystack telling us what went wrong. Now we aren't saying that Timebeat is going to go wrong, but it is nice to be able to quickly identify what went wrong, or if something is going to go wrong.
Rarely do engineers just have a look at a log file to see if all is running as expected, but sometimes they can hold important information to stop outages or increase the performance of the application.
So with Timebeat, we came up with a solution; why not log the important items (and a few informational items to) to the database and give them a dashboard in the front end for all to see and even alert on.
Logs, logs, and more logs:
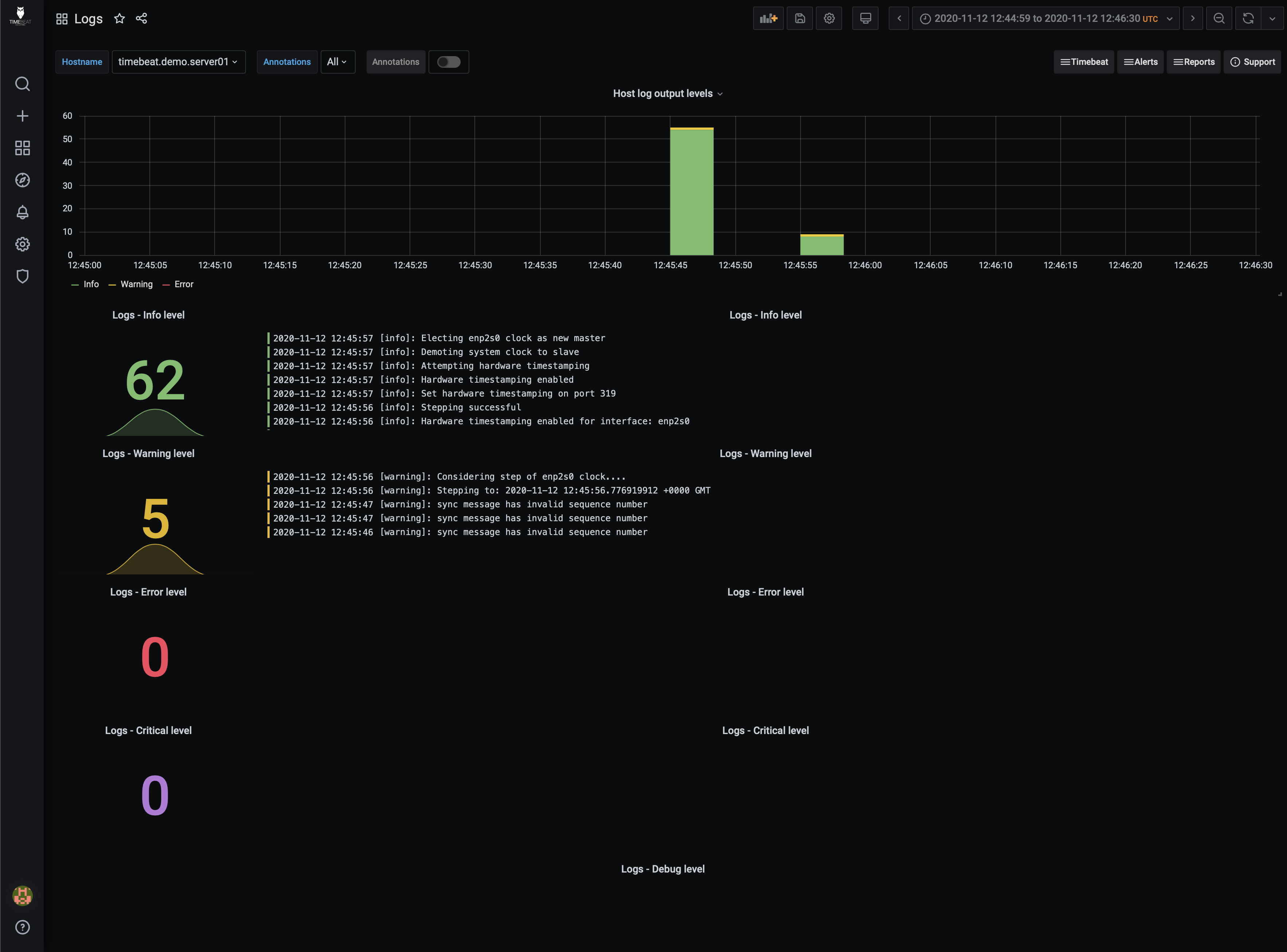
a view of the Logs page from when a device first starts up
The logs dashboard is broken up into simple easily recognisable items, and the colour coordination makes it that much easier at a glance.
The top bar chart is a running count of log items, colour coded for severity (Green= info, Yellow= warn, red= error, purple= critical and blue= debug).
This is useful for understanding how often informative logs are being logged, in most cases, this is populated on the start-up of the Timebeat application or when the application stops.
Below the bar graph is simple visualisation that represents the various log levels in their respective colour. The left-hand side depicts the count and the right hand visual is the log message itself so you know exactly what is going on with your application.
To go one step further, you can configure alerts based on text or event count. To understand what alerts you can configure speak to one of the Timebeat team.